-
하둡(HADOOP)버전별 특징HADOOP 이야기 2021. 4. 13. 16:50
하둡 V1.x
하둡 V1은 2011년 분산저장, 병렬처리 프레임워크를 정의 하였습니다. 분산저장은 네임노드(Name Node)와 데이터노드(Data Node)가 담당하였으며, 병렬처리는 잡트레커(Job Tracker)와 테스크트레커(Task Tracker)가 담당하여 처리 합니다.
분산저장 시스템을 HDFS라고 하는데, 네임노드는 블록들의 메타데이터를 가지고 있으며 데이터 노드는 데이터를 블록단위로 나누어 저장하는 역할을 합니다. 이러한 경우 네임노드를 문제가 생기게되면 데이터블록의 메타데이터가 없어지게 되므로 데이터를 사용 할 수 없게 됩니다. 반면 데이터노드를 문제가 생기게 되면, 네임노드에 하트비트를 보내지 않게 되고 이러한 정보를 받아 네임노드가 가지고 있는 정보를 가지고 문제가 생긴 데이터노드의 블록들을 다른 블록으로 복사를 하게 됩니다. 이러한 복사는 HDFS의 기본적인 3copy정책을 기반으로 정보를 가지고 오게 됩니다.
병렬처리는 잡트래커(Job Tracker)가 전체적인 진행상황을 관리와 자원 관리도 처리를 하고, 테스크트래커(Task Tracker)가 실제 작업을 진행합니다. 최대 4000개의 노드를 등록할 수 있으며, 맵슬롯, 리듀스 슬롯의 개수를 정해져 있습니다. 이러한 이유로 실행중에 맵슬롯으로 등록된 슬롯을 리듀스 슬롯으로 변경하는것은 불가능하며 맵이 진행중인 경우, 리듀스 슬롯은 대기상태에 남겨두게 되며, 실제 슬롯을 100% 활용을 할 수 없게 됩니다. 또한 잡트레커는 자원관리와 진행상황을 관리하는 2가지 업무를 병행하게 되는데 이로인해, 병목현상이 발생하게 됩니다.
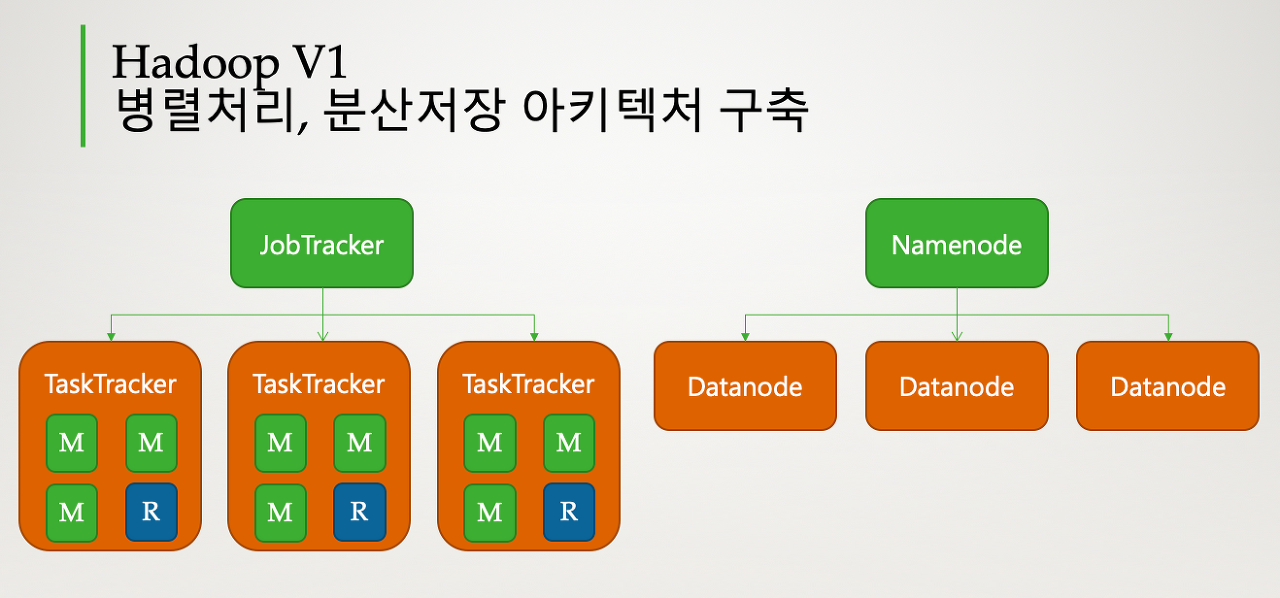
출처 : 위키독스-하둡, 하이브로 시작하기 하둡 버전별 특징 (https://wikidocs.net/26170) 하둡 V2.x
하둡 V2는 하둡 공식 사이트에서 지원하는 버전으로 잡트래커(Job Tracker)의 병목현상을 제거하기 위해 얀(YARN) 아키텍처를 도입했습니다. 얀(YARN)은 잡트래커가 담당하던 자원관리를 리소스 매니저(Resource Manager)와 (Node Manager)가 담당하고, 라이프 사이클관리는 애플리케이션 마스터(Application Master)가, 작업처리는 컨테이너(Container)가 담당하며, 클러스터당 최대 10,000개의 노드를 등록 할 수 있습니다.
얀(YARN)의 작업의 처리 단위는 컨테이너 입니다. 얀의 작업처리 과정은 아래와 같습니다.
작업제출 -> 애플리케이션 마스터 생성 -> 애플리케이션 마스터가 리소스 매니저에 자원요청 -> 컨테이너 할당 -> 컨테이너 작업
위 같은 방법으로 작업이 실행되며, 컨테이너는 작업이 끝나는 즉시 종료되게 되므로, 직전에 대기상태로 낭비되는 부분이 없기 때문에 클러스터를 더 효율적으로 사용 할 수 있습니다.
또한 중요한 정보로는 얀은 MapReduce 작업 이외의 작업도 컨테이너를 할당 받아 처리가 가능하기 때문에 우리가 많이들 알고 있는 Spark와 같은 다양한 컴포넌트도 실행 할 수 있습니다.
분산저장 시스템 부분에서는 Secondery NameNode 라는 보조 네임노드가 추가 되었습니다. 세컨더리네임노드는 fsimage를 병합하고 로그 파일을 주기적으로 편집하고 편집 로그 크기를 제한 내에서 유지합니다. 메모리 요구 사항이 기본 NameNode와 동일한 순서이기 때문에 일반적으로 기본 NameNode와 다른 시스템에서 실행됩니다.

출처 : 하둡 공식 사이트 (https://hadoop.apache.org/docs/r2.10.1/hadoop-yarn/hadoop-yarn-site/YARN.html) 하둡 V3.x
하둡 V2에서는 얀(YARN)의 도입이 있었다면 하둡 V3.x에는 이레이저코딩(Erasure Coding)이라는 HDFS 파일저장 방법이 존재 합니다.
이레이저코딩은 기존에 HDFS에서 장애 복구를 위해 파일을 기본 3Copy로 복제하였습니다. 이러한 경우, 1개의 파일이 2개를 더 복제하여 3개의 파일이 생성되며, 저장하고자 하는 파일의 용량이 3배 커지게 되므로 디스크 사용량의 비용이 증가하게 됩니다. 이러한 문제를 해결하기위해서 나온것이 이레이저코딩인데, 패리티 블록을 이용하여 1.5배의 디스크를 사용하여 기존의 1/2비율로 디스크 사용량이 떨어지게 됩니다. (위 내용은 이론적인 부분이며, 실제로 3.1.1의 이레이저코딩을 사용해 본 결과는 대량의 파일을 저장하는경우, 이레이저코딩이 원활하게 작동하지 않아 네임노드가 다운되는 현상을 지속적으로 발생 시켰습니다. 대략 20GB 정도)
또한 하둡 V3는 Java8을 지원하며, 고가용성을 위한 세컨더리 네임노드(secondaryNameNode)를 스탠바이 네임노드(Standby NameNode)라는 명칭으로 여러대를 구성할 수 있게 되었습니다.

출처 : 위키독스-하둡, 하이브로 시작하기 하둡 버전별 특징 (https://wikidocs.net/26170) 출처 :
위키독스-하둡, 하이브로 시작하기 하둡 버전별 특징 (https://wikidocs.net/26170)
위키독스
온라인 책을 제작 공유하는 플랫폼 서비스
wikidocs.net
하둡공식사이트v2(hadoop.apache.org/docs/r2.10.1/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html)
Apache Hadoop 2.10.1 – HDFS High Availability Using the Quorum Journal Manager
하둡공식사이트v3(hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HDFSErasureCoding.html)Apache Hadoop 3.3.0 – HDFS Erasure Coding
'HADOOP 이야기' 카테고리의 다른 글
Hadoop Cluster Setup (0) 2021.05.10 하둡 맵리듀스(MapReduce) (0) 2021.04.14 하둡 얀(YARN) (0) 2021.04.14 하둡(HADOOP)이란? (0) 2021.04.07